Slimmere software met machine learning
Oberon is geen specifiek machine learning bedrijf maar we maken er wel gebruik van. We zetten machine learning op een slimme manier in om de digitale platformen die we bouwen beter te maken.
Machine learning maakt de online wereld makkelijker
Automatische aanbevelingen helpen je bezoeker op weg. Bijvoorbeeld suggesties van opties bij een product of relevante informatie bij een zoekvraag. We doen voorspellingen van gebruikerswensen op basis van historische gegevens. Machine learning is zeer geschikt voor classificatie: het opdelen van de data in verschillende groepen. Hiermee helpen we experts om keuzes te maken. Conversational chatbots worden slimmer met behulp van machine learning. Hiermee kunnen ze meer dan alleen het herkennen van keywords in de tekst.
Machine learning, deep learning en AI
Verwarrende termen. Artificial intelligence (AI) is alles waarbij een computer slim gedrag vertoond. Een onderdeel daarvan is leren op basis van (grote) hoeveelheden data. Dat is machine learning.
Deep learning tenslotte is puur een referentie naar machine learning met modellen die uit veel lagen (deep) zijn opgebouwd.
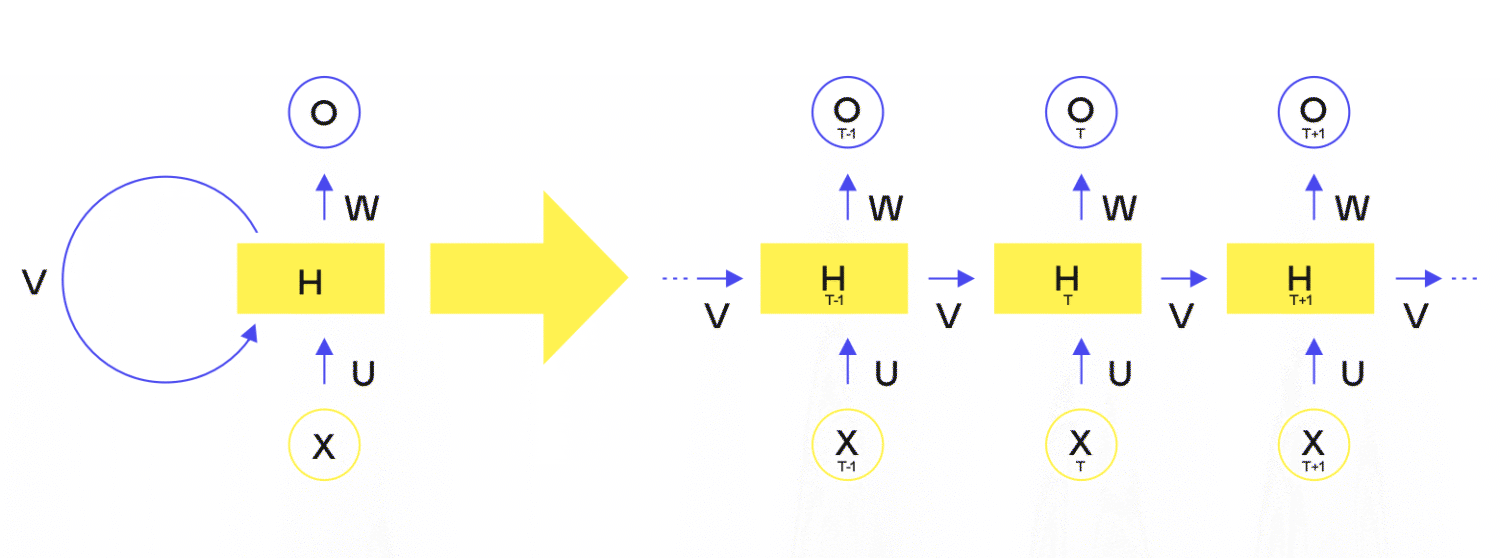
Hoe werkt dat nou?
De basis van machine learning is altijd een model. Dit is een complexe set van waardes met verbindingen ertussen. Dit model wordt getraind met behulp van bestaande data. Hoe meer data, hoe beter het model wordt. Na training kan het worden ingezet om uitspraken te doen op basis van nieuwe data.